Scansione di un originale come file PDF con dati di testo incorporati
Per abilitare le funzioni di ricerca e copia di testo in un'applicazione di visualizzazione di file PDF, è possibile incorporare i dati di testo in un PDF creato dai dati di scansione (funzione OCR).
È possibile utilizzare questa funzione anche per un file PDF in formato PDF ad alta compressione o PDF/A.

Per utilizzare questa funzione è necessaria l'unità OCR opzionale.
Funzioni che richiedono configurazioni opzionaliNon è possibile usare la funzione OCR nei seguenti casi:
Quando è selezionato TIFF o JPEG come tipo file.
La risoluzione selezionata è [100 dpi].
Premere [Scanner] nella schermata Home.

Posizionare l'originale sullo scanner.
Posizionamento di un originale da acquisirePremere [Impostaz.invio] nella schermata dello scanner.

Premere [Tipo file]
 [Altri].
[Altri].
Premere [PDF], [PDF alta compr.] o [PDF/A].
Premere [Impostazioni pagina] e selezionare [Pagina singola] per creare un file PDF per ciascuna pagina oppure selezionare [Multipagina] per creare un file PDF multipagina.
Premere [Impostazioni OCR], quindi specificare come eseguire l'OCR.
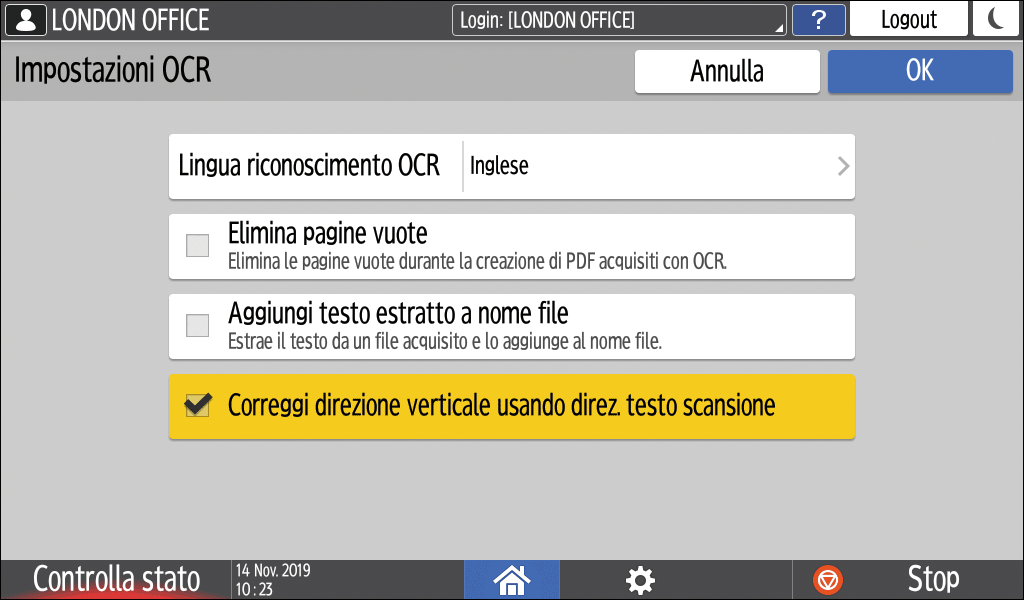
Lingua riconoscimento OCR: selezionare la stessa lingua utilizzata nell'originale da acquisire.
Elimina pagine vuote: le pagine vuote vengono rimosse dai dati acquisiti durante la creazione di un file PDF.
Aggiungi testo estratto a nome file: viene estratta la stringa di testo ritenuta più appropriata e aggiunta automaticamente al nome file. La stringa di testo viene estratta dalla prima pagina dei dati di scansione. Se la prima pagina non contiene testo, al nome file non viene aggiunta alcuna stringa.
Correggi direzione verticale usando direz. testo scansione: l'orientamento verticale dell'originale viene stabilito in base all'orientamento dei caratteri riconosciuti correttamente dal processo OCR.
Dopo aver completato l'impostazione dell'OCR, premere [OK].
Specificare la qualità dell'immagine in Tipo originale.

Per migliorare la precisione del riconoscimento, selezionare [Bianco e nero: Testo].Per inviare il documento acquisito a un indirizzo e-mail, premere [Mittente] e specificare il mittente.
L'utente che ha effettuato l'accesso e utilizza la macchina diventa il mittente dell'e-mail.
Acquisire documenti e inviare i dati di scansione via e-mailSpecificare la destinazione nella schermata dello scanner e premere [Avvio].

L'orientamento verticale di una pagina quasi vuota potrebbe non essere determinato correttamente.
È possibile facilitare la ricerca di una stringa in un file PDF con testo incorporato specificando di ignorare le forme a mezza larghezza e larghezza intera.
Il momento in cui iniziare la scansione della pagina successiva può richiedere più tempo a seconda del formato o della risoluzione dell'originale.
La funzione OCR può elaborare fino a 40000 caratteri per pagina.
La funzione OCR può riconoscere le seguenti lingue:
Inglese, Tedesco, Francese, Italiano, Spagnolo, Olandese, Portoghese, Polacco, Svedese, Finlandese, Ungherese, Norvegese, Danese, Giapponese.
La risoluzione effettiva può essere inferiore a 200 dpi quando un'immagine acquisita con una risoluzione da 200 dpi o maggiore viene ridotta specificando il rapporto di riproduzione. È possibile applicare la funzione OCR in tali casi, ma la precisione di riconoscimento del testo potrebbe essere inferiore.
A seconda delle forme o dei tipi di carattere, i caratteri potrebbero non essere riconosciuti correttamente.
Un file PDF senza testo incluso viene generato se la pagina acquisita non contiene una sezione che può essere riconosciuta come insieme di caratteri.
Nessun file PDF viene generato se tutte le pagine di un documento sono riconosciute come pagine bianche. In questo caso, assicurarsi di impostare gli originali correttamente e riprovare.
Una pagina vuota o la parte superiore o inferiore di una pagina potrebbero non essere riconosciute correttamente se la pagina acquisita presenta sbavature o punti di sporco o se può essere vista un'immagine sul retro della pagina.
Nessun carattere tipografico viene identificato mentre la funzione OCR viene applicata alla scansione. Se le larghezze dei caratteri stampati e incorporati differiscono, la posizione del testo incorporato può non corrispondere a quella del testo stampato sulla pagina acquisita.